
Want your software to run faster? We can port the code of your algorithms and software systems, parallelize and optimize existing implementations for high-performance (parallel, distributed or specialized) hardware.
Completed projects
1. Implementation of MCMC-algorithm (Markov chain Monte Carlo) for Intel Xeon PHI.
Initially, researchers of University of Helsinki, National Institute for Health and Welfare, Helsinki, Finland have implemented a single-threaded version of the algorithm for the simulation of the spread of A(H1N1)pdm09 flu in Finland. To obtain statistically significant results they were to increase the speed of the algorithm to obtain results on a larger sample set. RunParallel team has ported the implementation to the heterogeneous system with Intel Xeon PHI accelerator. For more on computational methods refer to appendix 3 for the article “Revealing the True Incidence of Pandemic A(H1N1)pdm09 Influenza in Finland during the First Two Seasons — An Analysis Based on a Dynamic Transmission Model”. 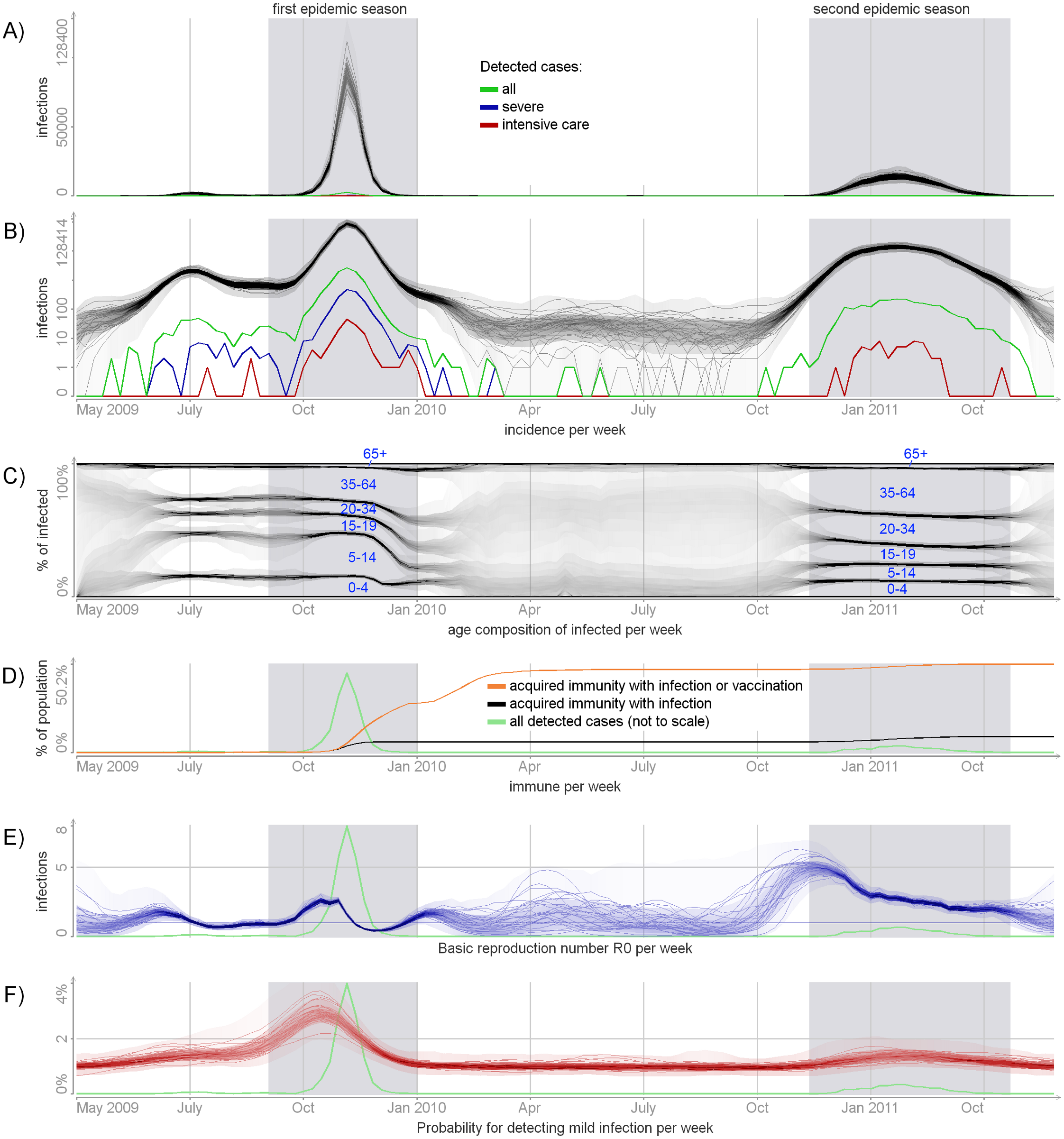
2. MC# и ParallelC# samples development.
Together with MC# (PSI RAS, MC#) and ParallelC# projects’ teams we developed implementations of different algorithms (sparse matrix multiplication, FFT, RandomAccess algorithm, an algorithm for finding prime numbers) in order to demonstrate the possibility of automatic porting this algorithms to GPGPU-accelerators and MPI-systems.